整合升级BTM和MoE,大模型专业领域能力高效训练法BTX诞生
2024-03-06 | 魔鸽运营组
出品丨AI 科技大本营(ID:rgznai100)
整合多个专家大模型到一个混合专家大模型(Mixing Expert LLMs into a Mixture-of-Experts LLM),Meta在人工智能机器学习领域取得新的高效方法突破。
最近,Meta基础人工智能研究(FAIR)团队发布了名为Branch-Train-MiX (BTX)的方法,可从种子模型开始,该模型经过分支,以高吞吐量和低通信成本的并行方式训练专家模型。Meta FAIR的成员之一Jason Weston在其X上发文介绍了这一进展。
BTX能够提高大型语言模型(LLMs)在多个专业领域的能力,如编程、数学推理、世界知识等细分专业领域。这些专家模型在训练后,其前馈参数被整合到混合专家(Mixture-of-Expert, MoE)层中,并进行平均参数的MoE微调,以学习在token级别上的路由。
BTX概括了两种特殊情况,即没有MoE微调阶段来学习路由的BTM(Branch-Train-Merge)方法,以及省略了异步训练专家阶段的稀疏升级方法,是BTM与MoE两种方法的优势结合与改进。
与其他方法相比,BTX 实现了高准确性与效率的权衡。与Branch-Train-Merge相比,BTX最终模型是一个统一的神经网络,可以进行进一步的监督微调(SFT)或人类反馈强化学习(RLHF)微调。与纯MoE训练相比,BTX在计算效率、训练吞吐量,以及不同领域的任务上都表现得更为出色。
研究团队在实验使用了Llama-2 7B模型作为种子模型,并在数学、编程和维基百科等不同数据子集上训练专家LLMs。通过将原始Llama-2 7B权重作为第四个专家模型加入,研究者们对合并后的MoE模型进行了相对较短的微调。
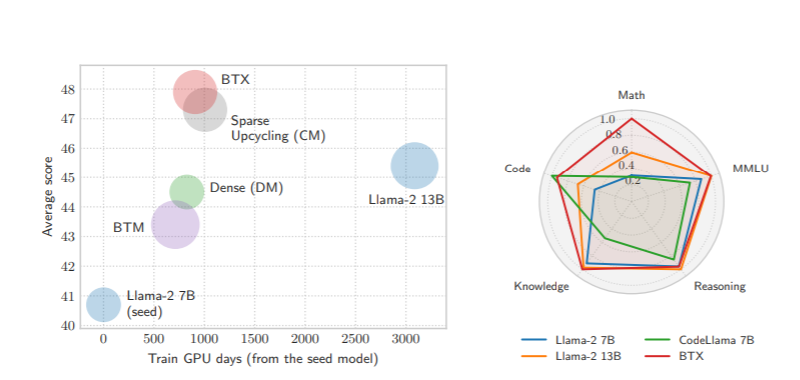
实验结果表明,BTX模型在多个领域的任务上相比种子模型有显著提升,尤其是在数学和编程相关任务上,同时保留了在原始能力上的表现,避免了灾难性遗忘。BTX在所有任务上都优于BTM,展示了通过MoE微调学习路由的好处。与稀疏上循环(sparse upcycling)等纯MoE训练相比,BTX在计算效率上更优,训练吞吐量更高,且在编码、数学推理和维基百科不同领域的任务上表现更平衡。
Jason Weston是美国 Meta AI 的研究科学家,也是纽约大学的客座研究教授。他的兴趣在于先进的机器智能,重点关注的领域是推理、记忆、感知、交互和通信。他发表过100 多篇论文,并获得了ICML(国际机器学习大会)和ECML(欧洲机器学习大会)最佳论文奖。他凭借与Ronan Collobert 合作完成的一篇论文作品《自然语言处理的统一架构:具有多任务学习的深度神经网络》,在2008年获得ICML时间考验奖。
Jason Weston所在的Meta的基础人工智能研究(FAIR)团队,致力于进一步加深人们对新领域和现有领域的基本理解,研究领域涵盖人工智能相关的所有主题。
注:原网站 https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/136754901?spm=1000.2115.3001.5927